
Recorded Data Labeling
Meta-Information
Origin: Gustavo Garcia Padilla / Hella, Fabian Diegmann / Hella, Sadri Hakki / Hella
Written: July 2018
Purpose: Generation of Ground Truth Data related to the relevant objects of a use case (e.g. Intersection Crossing, Valet Parking, …) from recorded data. In a first part of the process the relevant objects are detected automatically using Deep Learning technology. The generated hypotheses about class, position and size of the detected objects are sent to the second part of the process for verification/correction and additional labeling by a human labeler.
Context/Pre-Conditions:
– Deep Learning Network (DLN): Compared to classical engineered image processing techniques, a DLN can quickly be adapted to new use cases (e.g. new object classes) with very limited engineering effort generally gives a good robustness across scenarios. Hence it is the standard solution for this sort of backend processing.
– An initial training phase is required: The DLN must be trained to detect the relevant objects of the use case in the execution phase. The training data consist of labeled camera data corresponding to the objects to be detected.
– Labeling Jobs: Specifications of the pre-labeling task, verification/correction task and of the labeling task defining the data to be processed and their quality and the relevant objects with their attributes and required accuracy. This jobs are generated by a human operator from the Data Management Tool and sent to the Pre-Labeling and Labeling Tool.
To consider:
– The initial training phase can be expensive depending on the required accuracy and if the training data has to be labeled by an expert human labeler.
– A re-training phase is required if during the execution phase of the pre-labeling tool his overall performance or his performance for specific use cases or objects is not satisfactory.
Structure
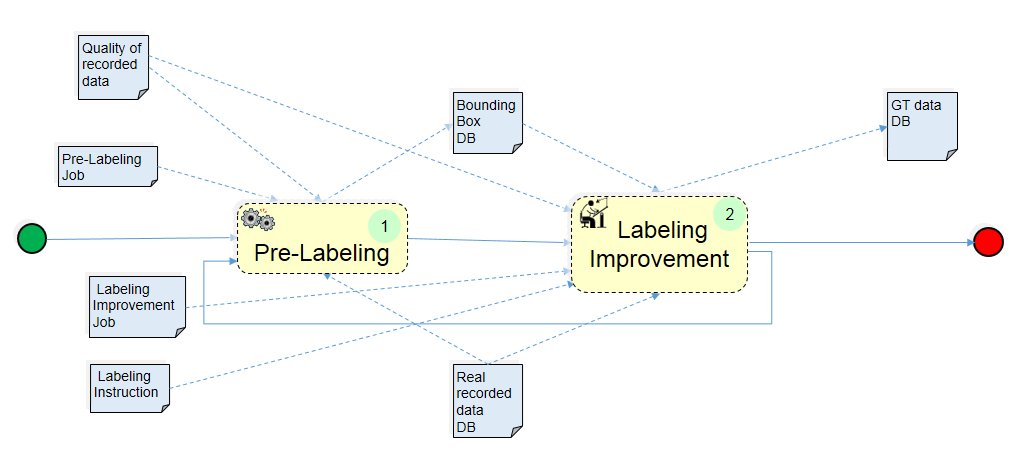
Structure Refinement:
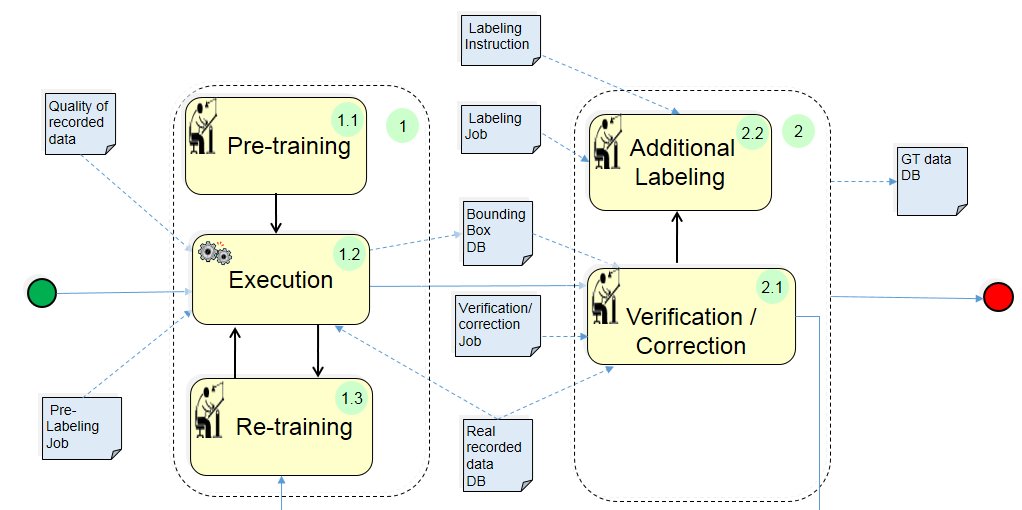
Participants and Important Artefacts
Real recorded data: Visual data (images, videos etc.). Input to the Labeling Pattern.
Quality of recorded data: Information related to the quality of the recorded data, e.g. color depth, pixel resolution.
Pre-labeling job: Input to the Pre-labeling tool defining the recorded camera data (file list) to be pre-labeled, the DLN to be applied to detect the use case relevant objects to be pre-labeled.
Pre-Labeling: Automatic generation of hypotheses for object class and bounding box data (position and size in image coordinates).
Bounding Boxes (BB): minimal, axis-parallel rectangles around relevant objects found in real recorded data.
Verification/correction job: Input to the Labeling tool defining the pre-labeled data (file list), the relevant pre-labeled objects to be verified/corrected and their bounding box required accuracy.
Labeling job: Input to the Labeling tool defining the verified/corrected pre-labeled data (file list), the additional relevant objects and their attributes to be labeled and their accuracy.
Labeling Instructions: Detailed instructions for the human labeler including special cases like occlusion and truncation.
Labeling Improvement: Verification/correction and additional labeling by human labeler.
GT data: Output of the Labeling Pattern, i.e. labeled data, also called “Ground Truth” (GT). For identified objects at least category and BB.
Actions and collaborations
(1) Pre-Labeling:
(1.1) Pre-Training: The Deep Learning Network (DLN) must be trained to detect the relevant objects of the use case in the execution phase. The training data consist of labeled camera data corresponding to the objects to be detected.
(1.2) Execution: The trained DLN is used for the automatic labeling of new, non labeled data.
(1.3) Re-Training: If during the execution phase of the pre-labeling tool his overall performance or his performance for specific use cases or objects is not satisfactory, then a re-training with extended training data can improve the results.
(2) Labeling Improvement:
(2.1) Verification/Correction: The pre-label hypotheses are verified/corrected by a human operator.
(2.2) Additional Labeling: Additional labels specified in the Labeling Job can be generated by a human operator.
Discussion
Benefits: Ground truth data proposals about the position, size and class of relevant objects are generated automatically. These hypotheses can then be reviewed by a human operator for verification. The mere verification process is expected to be substantially faster than the full manual annotation.
Limitations: A Deep Learning Network (DLN) can only recognize objects, that it has been trained to recognize. For example when used to do vehicle pre-annotation, a data base of labeled examples of vehicles needs to be provided first.
Application hints:
– Due to the power of generalization of DLNs, it may be possible to use data bases from different projects for initial training. This may give a sufficient quality to get started and the network performance can later be improved by using incremental re-training steps. The main advantage of the DLN-based method is that it is an incremental re-training process, not done from scratch.
– Ideally the data should be as close as possible to the target project settings regarding sensor type, resolution, sensor control, frame rate and other parameters. Note however, that due to the power of generalization of DLNs, it may be possible to use data bases from different projects for initial training. This may give a sufficient quality to get started and the network performance can later be improved by using a re-training step.
Application Examples
ENABLE-S3 Use Case 2 “Intersection Crossing”: The pattern was applied for the detection of relevant objects in intersection crossing scenarios.
ENABLE-S3 Use Case 6 “Valet Parking”: The pattern was applied for the detection of relevant objects in Valet Parking scenarios.
.
Relations to other Patterns
| Pattern Name | Relation* |
| Scenario Representativeness Checking | This pattern is sub-pattern of the Scenario Representativeness Pattern |
| Abstract Scenario Mining | This pattern prepares (visual) data for extracting scenarios |
* “this pattern” denotes the pattern described here, “that pattern” denotes the related pattern