
Get Confidence In Generated Code
Meta-Information
Origin: Darren Sexton / RICARDO
Written: October 2014
Purpose: To increase confidence that the function and behaviour of code matches that expressed (and validated) in an implementation model. Actual defects in the code-generation are expected to be low, but deviations may also be caused by how the code generator is configured, use model annotations, math precision on the embedded target, and how it is understood by engineers. There may also be differences in the semantics used by the model interpreter, (verification engine), and code generator.
Context/Pre-Conditions: Code is generated from an implementation model, code generator or options not 100% understood or trusted.
To consider: Thorough B2B testing presumes test generation from implementation model that covers implementation (the generated code). Required expertise level: low. B2B testing must be easy and cheap to deploy.
Structure
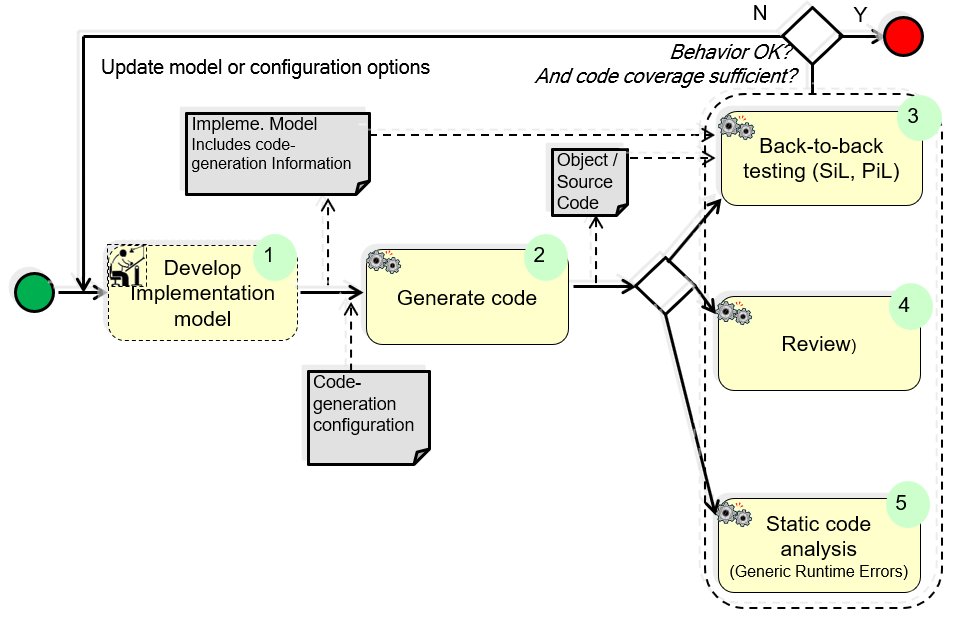
Participants and Important Artefacts
B2B testing: (back-to-back testing)
– Identical test stimuli are run on the implementation model in simulation and on the generated code (on host and / or target environment) and the equivalency of the results compared.
– Code coverage should be measured and evaluated and compared to the chosen completion criterion.
Implementation Model: A model that described the intended behavior of the system being developed, so concretely and in such detail that code can be generated from it. This may also include annotations used by the code generator.
Code Generator: Creates executable code from the implementation model. It usually involves two, sometimes independent, steps: generation of source code (typically C-language) and cross compilation to the intended target.
Review: Manual review, at least of a code sample is recommended to ensure that certain parts of the code generator is correctly understood. Such an understanding of a given code generator is necessary to inform modelling guidelines regarding constructs to avoid known problems, inefficient code etc.
.
Actions / Collaborations
(1) The models are made ready for code generation.
(2) The code is generated; for back-to-back testing it is possible to request the code generator to generate the code.
(3) B2B testing is performed on generated code (SiL), or compiled and generated for target code (PiL).
– It is recommended that model authors perform this activity as they augment the model for code generation (e.g. on subsystems) to allow early feedback of errors.
(4) The informal review ensures that the engineering team understand how modelling style affects the code generator; thus it is not a review for correctness of translation, but instead a learning method.
– The „review“ is thus informal – it does not form part of the overall verification plan.
– It is recommended that this is performed intially as the code generation configuration is set-up, to allow early feedback to modelling guidelines (particularly when a new version of the code generator is used).
– It is recommended that this is also performed, on a sample basis, as software features are implemented to check the code based on the style of models actually being deployed.
(5) Static code analysis for certain run-time errors is largely unrelated to confidence the code is equivalent to the model, but increases confidence in the quality of the code generally.
– This should be performed only once the code-model equivalence activities have been performed, to avoid repeating the activity unnecessarily.
.
Discussion
Benefit: When the generated code is trusted, more V&V can be pushed to the model-level, thus becoming cheaper, and with higher coverage.
Comments (from Darren Sexton, edited by Wolfgang Herzner): In general there are two approaches to gaining confidence that auto-generated code is a faithful translation of implementation models. The first means is to have sufficient confidence in the code generator (and how it is used) that it is not necessary to perform significant checks on the output. The second, more widely used, approach is to perform some mix of verification techniques to confirm the code matches the model. This second approach can be met through one or more of:
Review:
– Review generated code manually against the implementation models.
– This is time-consuming and must be repeated each time the code is regenerated.
– Manual reviews compare source code against the models. This means defects in the cross-compiler would not be detected.
Analysis:
– The implementation models and code can be converted to a notation that allows static analysis to compare they have equivalent functionality; such analysis may or may not use formal methods technologies.
– Current state-of-the-art tools currently suffer many limitations (2014), for example in the types of modelling constructs they support; thus for many applications they may not be practically deployable.
– Current state-of-the-art tools compare source code against the models. This means defects in the cross-compiler would not be detected.
Test (B2B):
– Identical test stimuli are run on the implementation model in simulation and on the generated code (on host and / or target environment) and the equivalency of the results compared.
– Defects in the cross-compiler or its configuration will likely be detected.
For back-to-back testing, the test stimuli can either be created or test stimuli re-used that were created for other reasons, principally from functional testing. Re-using existing test stimuli is efficient but means the back-to-back testing cannot be performed until such test stimuli are available. Creating specific test stimuli would add a significant amount of effort if not highly automated.
For maximum efficiency, the approach must support early day-to-day usage by the engineers responsible for augmenting design models with code generation information (such as data-types, fixed-point scaling), as well as supporting the formal verification. Early usage by model authors can increase efficiency by eliminating certain classes of defects before later verification phase; this reduces re-work overhead and enables defects to be eliminated much earlier.
The generated test stimuli are derived from the implementation model, with the aim of achieving high structural code coverage and coverage of similar properties. Thus the tests check whether the model and code are equivalent and each has been exercised thoroughly, but not the correctness of the implementation model. Since the test stimuli are derived from the implementation model they can be used as soon as the model is constructed.
Not all differences between the code and the implementation model are necessarily unacceptable. For example, very small rounding errors in floating point values may occur between the simulation on the host and the executing code on the target. These can be a significant source of “noise”, diverting effort and making it harder to gain acceptance among end-users. Therefore it is recommended that small default tolerances are defined up-front and taken into account during the comparison of results.
Ultimately, confidence must be gained that the final object code running on the target is sufficiently equivalent to the implementation models. Thus processor-in-the-loop (PiL) testing gives greater confidence that running generated code in a host environment, known as Software-in-the-Loop (SiL); when PiL testing is used then running test stimuli in SiL as well is not strictly necessary since the results from PiL are sufficient to detect and effects SiL test could find. In such cases, SiL testing may still be useful, due to limited availability of target hardware or the speed of running the tests. Thus in practice SiL testing is especially useful for gaining a measure of early confidence in the code generation, whilst PiL testing can be reserved for later verification activities.
The use of any automated technique to compare code with implementation models must not preclude gaining an understanding of the code generator. Such an understanding of a given code generator is necessary to inform modelling guidelines regarding constructs to avoid known problems, inefficient code etc. Therefore the back-to-back testing should be complemented by some level of code inspection (at least for the purposes of understanding the code generator).
From Brian Nielsen:
– Addition to the Analysis method mentioned on slide 5: it refers to equivalence checking, which is rather inappropriate at this abstraction level.
– The pattern may be strengthened by including other code analysis techniques.
.
Application Examples
MBAT Automotive Use Case 1 (Brake by Wire) / Scenario 11 (Static source code analysis):
Participants / Artefacts:
User: Volvo
Tools: Simulink, TargetLink, BTC Embedded Tester, AbsInt Astrée
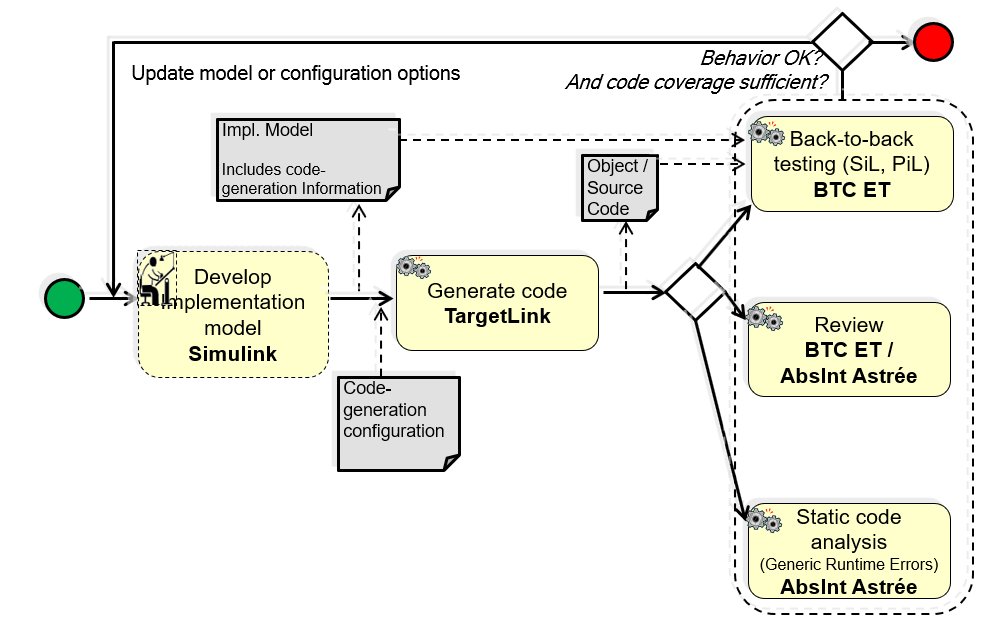
MBAT Automotive Use Case 5 (Transmission Controller Product Line) / Scenario 02 (Analysis of Implem. Model) & Scenario 03 (Automatic TCG):
Participants / Artefacts:
Implementation Model
– Operating on Simulink/Stateflow model
– Note: Existing activity outside the scope of MBAT
B2B Testing
– Tools: BTC-EmbeddedTester
– Operating on TargetLink model & code
Code Generator
– Tools: dSPACE TargetLink
– Operating on TargetLink model
– Note: Existing activity outside the scope of MBAT
Review
– Tools: none
– Performed on code
.
Relations to other Patterns
| Pattern Name | Relation* |
| Target MBA&T by Static Code Analysis | That pattern uses TCG from implem. models to check suspect areas |
| MBA-based Runtime Behaviour Verification | That pattern can be used instead of this pattern if code is developed manually |
* “this pattern” denotes the pattern described here, “that pattern” denotes the related pattern